
刚才现在,Grok4跑步分数已经暴露出来:“最后的
发布时间:2025-07-08 09:42
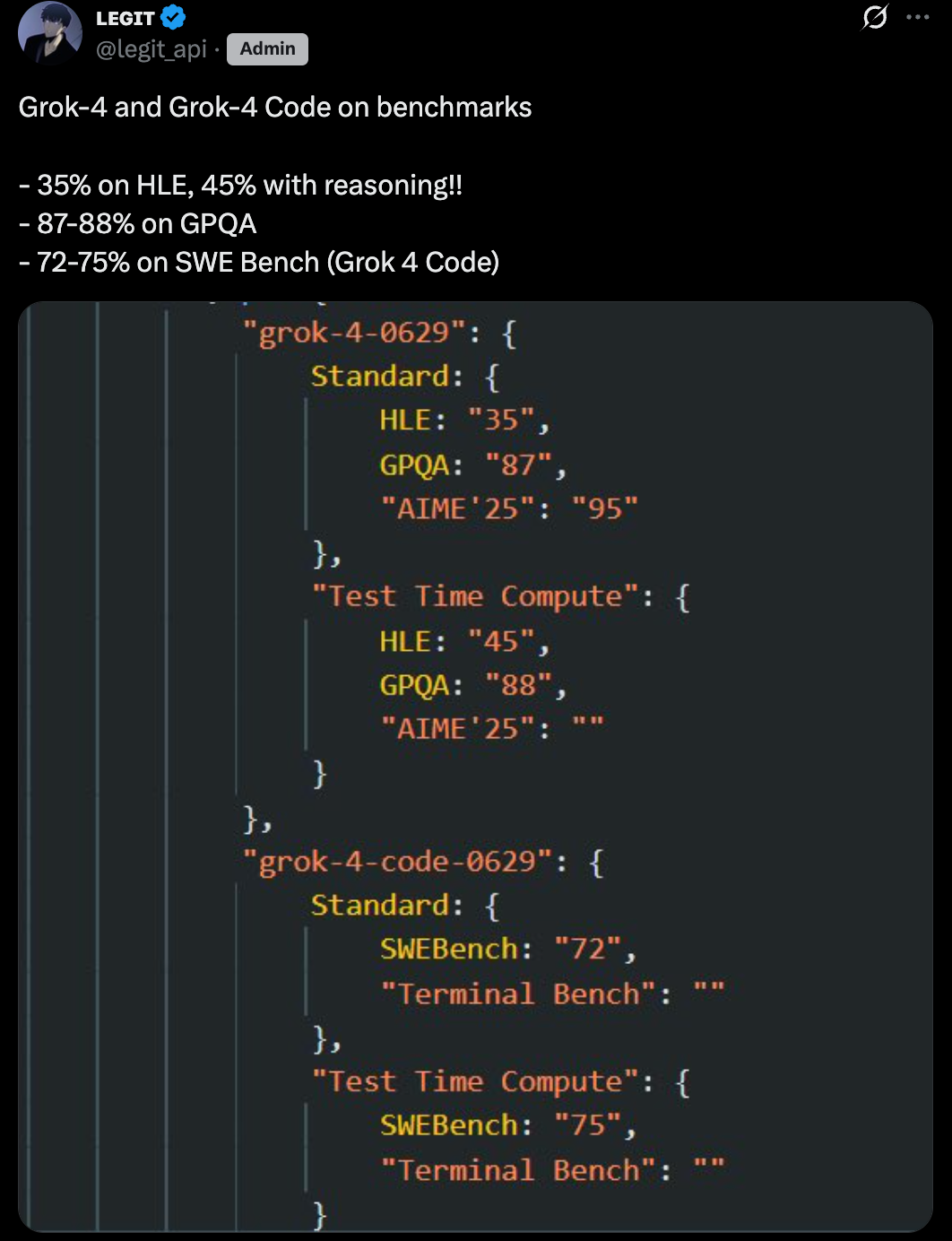 马斯克是否有效建立帐篷并熬夜形成它?如此高的分数尚未发布。刚才,怀疑Grok 4和Grok 4代码的基准的结果被怀疑是传播的。 X Blogger @legit_api发布了HLE(人文学科上一次考试)的标准Groung Grok 4为35%,使用推理方法后增加到45%。 GPQA为87-88%;而Grok 4代码在SWE台上得分为72-75%。这个运行标记是什么意思?一些网络将其与诸如OpenAi O3和Claude Opus等竞争模型进行比较。Grok4分的HLE大约35%,使用推理方法后增加到45%,这是OpenAI O3的最佳公共分数(约20%),大约是GPT-4O的最佳公共分数。您应该知道,HLE是伊桑免费试验测试,其预言的随机预言几乎为5%,因此很难提高每个百分比。与GPQA(研究生级的物理和天文学问题),Grok 4得分为87-88%,是与OpenAI O3的最高表现相当,并显着超过Claude 4的作品约75%。 Grok 4在Aime 25(2025 American Mathematics Olympiad)上得分95%,这是Claude 4 Opus的34%以上,略高于OpenAI O3的80-90%(取决于心态)。此外,Grok 4代码的SWEBENCH分数对应于Claude Opus 4的72.5%,略高于OpenAI O3的71.7%。在终端板凳上,Claude 4 Opus导致43%的分数,XAI尚未在Grok-4上发布数据。其中,网民中最讨论的事情是,Grok 4在HLE中达到了惊人的45%,几乎是Gemini 2.5 Pro的Marka的两倍。如果泄漏测试的结果为真,则意味着Grok 4通过AI基准上的最困难水平。一些网民还建议关注“标准”标记,该标记认为这是公共模型的基准,并且推断标记可能参与了实验调整。但是,有些nEtizens表示怀疑,认为Grok 4的HLE得分不太可能很高,因此应该存在问题。 Netizen提供的原因是Xai最后一次报告了一次尝试使用其他模型的结果,但使用不同的报告方法为自己的模型使用。 @legit_api回答说数字是正确的,但我们不知道调整。除了HLE外,一些网民已经结束了今天的所有基准结果 - gro grok 4似乎是“合理的”。但是HLE如何获得如此高的分数?毕竟,此基准测试包含许多非隐形信息提取。也许每个人都必须等待模型在答案之前正式发布。实际上,早在7月1日,外国媒体TestingCatalog发表了一篇有关GROK 4系列模型的文章信息,将在XAI开发人员中心控制台网站上以及旗舰模型GROK 4和编程模型GROK 4代码放置。屏幕申请表明,Grok 4仅支持文本模式,并且将尽快启动图像和其他操作的视觉,生成。 GROK4支持大约130,000个Windows的令牌上下文,比许多切割模型小,这可能表明XAI优化了理解速度和实时的速度,而不是追求最大的长上下文表现。从功能的角度来看,Grok 4将包括功能调用,结构化输出和识别功能。一些网络还挖掘了XAI开发人员中心控制台的源代码。这些代码表明,Grok 4是一种通用模型,在自然语言,数学和推理中“无与伦比的功能”,并在6月29日当地时间完成了培训,口号“想想更大,更聪明”。屏幕截图还表明,Grok 4代码是一种用于编程的模型,用户可以在此处直接提出代码问题或直接嵌入代码编辑器中的代码问题。上周,马斯克在推文说,他正在“整夜开发Ng Grok 4”,并且该模型的开发“发展良好”,但仍然需要“最后的良好培训”,尤其是在专业代码模型方面。因此,马斯克(Musk)自上个月年底以来就建立了一个办公室,以便睡觉并致力于他的工作。这种泄漏的分数不仅刺激了网络的小心脏,还刺激了许多AI技术公司。是Grouk 4,但并不是完整的,基准结果被暴露出来,也许Grok 4将在几天内正式发布。如果结果是正确的,无论是改变体系结构还是扩展规模,Grok都会推动AI模型的浪潮的形成,让我们拭目以待。
马斯克是否有效建立帐篷并熬夜形成它?如此高的分数尚未发布。刚才,怀疑Grok 4和Grok 4代码的基准的结果被怀疑是传播的。 X Blogger @legit_api发布了HLE(人文学科上一次考试)的标准Groung Grok 4为35%,使用推理方法后增加到45%。 GPQA为87-88%;而Grok 4代码在SWE台上得分为72-75%。这个运行标记是什么意思?一些网络将其与诸如OpenAi O3和Claude Opus等竞争模型进行比较。Grok4分的HLE大约35%,使用推理方法后增加到45%,这是OpenAI O3的最佳公共分数(约20%),大约是GPT-4O的最佳公共分数。您应该知道,HLE是伊桑免费试验测试,其预言的随机预言几乎为5%,因此很难提高每个百分比。与GPQA(研究生级的物理和天文学问题),Grok 4得分为87-88%,是与OpenAI O3的最高表现相当,并显着超过Claude 4的作品约75%。 Grok 4在Aime 25(2025 American Mathematics Olympiad)上得分95%,这是Claude 4 Opus的34%以上,略高于OpenAI O3的80-90%(取决于心态)。此外,Grok 4代码的SWEBENCH分数对应于Claude Opus 4的72.5%,略高于OpenAI O3的71.7%。在终端板凳上,Claude 4 Opus导致43%的分数,XAI尚未在Grok-4上发布数据。其中,网民中最讨论的事情是,Grok 4在HLE中达到了惊人的45%,几乎是Gemini 2.5 Pro的Marka的两倍。如果泄漏测试的结果为真,则意味着Grok 4通过AI基准上的最困难水平。一些网民还建议关注“标准”标记,该标记认为这是公共模型的基准,并且推断标记可能参与了实验调整。但是,有些nEtizens表示怀疑,认为Grok 4的HLE得分不太可能很高,因此应该存在问题。 Netizen提供的原因是Xai最后一次报告了一次尝试使用其他模型的结果,但使用不同的报告方法为自己的模型使用。 @legit_api回答说数字是正确的,但我们不知道调整。除了HLE外,一些网民已经结束了今天的所有基准结果 - gro grok 4似乎是“合理的”。但是HLE如何获得如此高的分数?毕竟,此基准测试包含许多非隐形信息提取。也许每个人都必须等待模型在答案之前正式发布。实际上,早在7月1日,外国媒体TestingCatalog发表了一篇有关GROK 4系列模型的文章信息,将在XAI开发人员中心控制台网站上以及旗舰模型GROK 4和编程模型GROK 4代码放置。屏幕申请表明,Grok 4仅支持文本模式,并且将尽快启动图像和其他操作的视觉,生成。 GROK4支持大约130,000个Windows的令牌上下文,比许多切割模型小,这可能表明XAI优化了理解速度和实时的速度,而不是追求最大的长上下文表现。从功能的角度来看,Grok 4将包括功能调用,结构化输出和识别功能。一些网络还挖掘了XAI开发人员中心控制台的源代码。这些代码表明,Grok 4是一种通用模型,在自然语言,数学和推理中“无与伦比的功能”,并在6月29日当地时间完成了培训,口号“想想更大,更聪明”。屏幕截图还表明,Grok 4代码是一种用于编程的模型,用户可以在此处直接提出代码问题或直接嵌入代码编辑器中的代码问题。上周,马斯克在推文说,他正在“整夜开发Ng Grok 4”,并且该模型的开发“发展良好”,但仍然需要“最后的良好培训”,尤其是在专业代码模型方面。因此,马斯克(Musk)自上个月年底以来就建立了一个办公室,以便睡觉并致力于他的工作。这种泄漏的分数不仅刺激了网络的小心脏,还刺激了许多AI技术公司。是Grouk 4,但并不是完整的,基准结果被暴露出来,也许Grok 4将在几天内正式发布。如果结果是正确的,无论是改变体系结构还是扩展规模,Grok都会推动AI模型的浪潮的形成,让我们拭目以待。